旷视文本检测与识别综述笔记

Introduction
Basic pipeline
- Detection+Recognition
- End-to-end

Challenges for general text detection and recognition
- Diversity and variability
- different languages/color/fonts/size/orientations/shapes
- Complexity and interference of background
- similar patterns/occlusions
- Imperfect image conditions
- Low resolution/shot angle/blurred(unfocused)/noise/light
Methods before DL
Text detection
CCA (Connected Components Analysis):连通域分析法
提取出包含文本的候选区域(color clustering/extreme region extration)
从候选区域中过滤背景,即分割出文本类(特征提取,分类/分割)
- 特征:MSRE/SWT/SIFT/SURF/LBP/灰度共生矩阵等
- 分类器:Kmeans/KNN/SVM/NN/DecisionTree等
Huang et al., 2013; Neumann and Matas, 2010; Epshtein et al., 2010; Tu et al., 2012; Yin et al., 2014; Yi and Tian, 2011; Jain and Yu, 1998
SW (Siliding window):滑动窗口法
- 利用不同大小的滑动窗口对窗口区域进行二分类(包含/不包含文本)
- 通过形态学操作/CRF/Graph-based-method等对窗口进行合并
Lee et al., 2011; Wang et al., 2011; Coates et al., 2011; Wang et al., 2012
Text recognition
- 基于特征的方法
- 划分子问题
- 二值化(text binarization)->文本行切分(text line segmentation)->字符划分(character segmentation)->单字符识别(single character recognition)->单词校正(word correction)
feature-based: Shi et al., 2013; Yao et al., 2014; Rodriguez-Serrano et al., 2013, 2015; Gordo, 2015; Almazan et al., 2014
text binarization: Zhiwei et al., 2010; Mishra et al., 2011; Wakahara and Kita, 2011; Lee and Kim, 2013
text line segmentation: Ye et al., 2003
character segmentation: Nomura et al., 2005; Shivakumara et al., 2011; Roy et al., 2009
single character recognition: Chen et al., 2004; Sheshadri and Divvala, 2012
word correction: Zhang and Chang, 2003; Wachenfeld et al., 2006; Mishra et al., 2012; Karatzas and Antonacopoulos, 2004; Weinman et al., 2007
End-to-end (detection+recognition)
- Wang et al., 2011:nearest-neighbor classifier+HoG
- Neumann and Matas, 2013:decision delay ap- proach+dynamic programming algorithm
Wang et al., 2011; Neumann and Matas, 2013
Methods based on DL
Text detection
早期尝试
基于目标检测的方法
Anchor-based
- TextBoxes (Liao et al., 2017):anchor-based, SSD [code]
- EAST (Zhou et al., 2017):anchor-based, u-net, simple pipeline and real-time speed [code]
Region proposal
- Ma et al., 2017: solve text of arbitrary orientations [code]
- FEN (Zhang et al., 2018)
Specific task/case (w/o sub-text)
- ITN (Wang et al., 2018): multi-orientated text [code]
- Zhang et al., 2019: irregular text
- Wang et al., 2019b: irregular text
Sub-text components: better flexibility over shapes and aspect ratios of text
- Use NN to predict local attributes or segments
- Post-processing to re-construct text instance
Text recognition
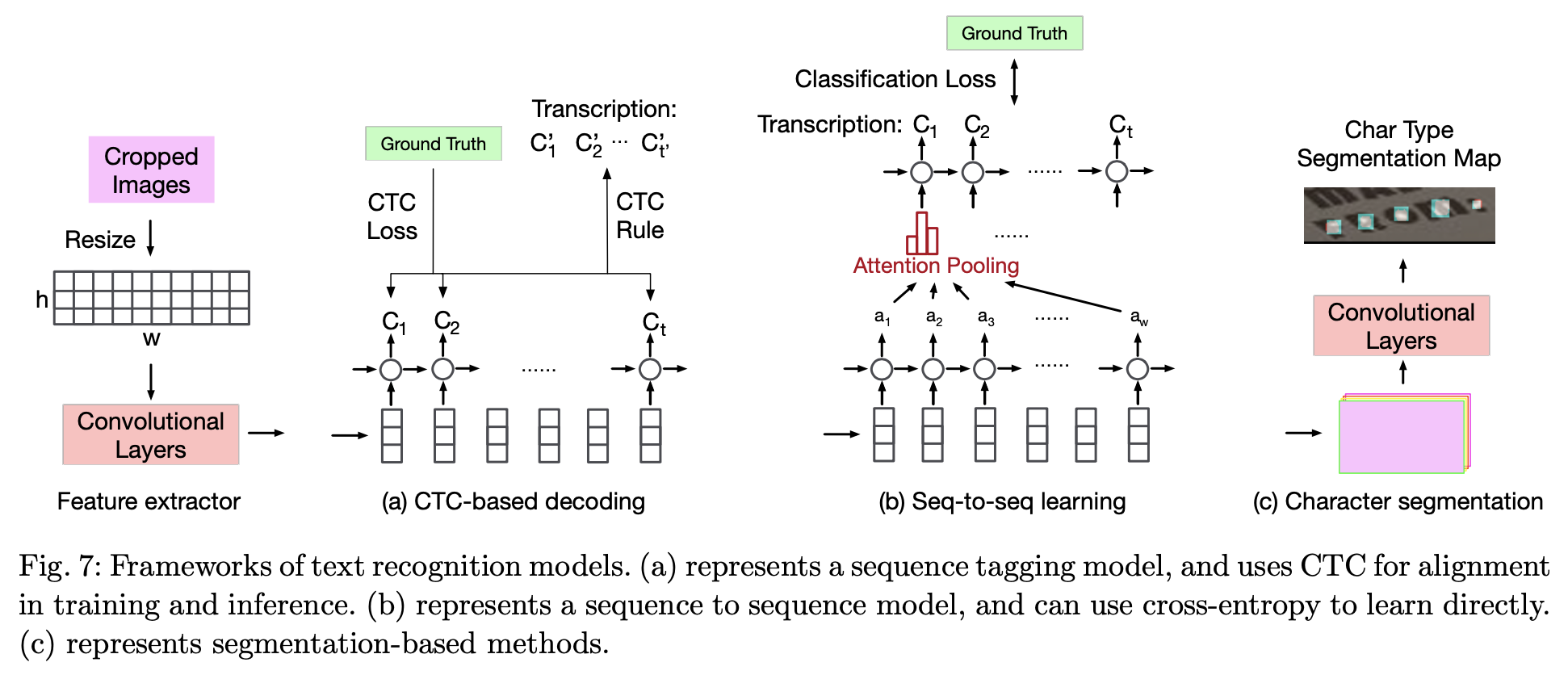
CTC-based (Connectionist Temporal Classification,一种时序分类算法) (CNN+RNN+CTC)
- CNN layer:CNN Encoder提取文本图像特征,形成若干特征序列
- RNN layer:RNN进一步提取文本序列特征
- Transcription layer (CTC loss):CTC解决字符对齐问题
Encoder-Decoder (CNN+Seq2Seq+Attention)
- CNN layer:CNN Encoder提取文本图像特征,形成若干特征序列
- Seq2Seq+Attention:好处是输出向量长度可以与输入不同
- Transcription layer (Classification loss)
Irregular text Case
End-to-end (Detection+Recognition/Text Spotting)
- Two-stage pipeline: feature map instead of images are cropped and fed to recognition module
- One-stage pipeline: predict character and text bounding boxes as well as character type segmentation maps in parallel

Auxiliary techniques that support detection and recognition
- Synthetic Data
- Weakly and Semi-Supervision
More paper reference
https://github.com/Jyouhou/SceneTextPapers
Datasets

| Dataset (Year) | Image Num (train/test) | Text Num (train/test) | Orientation | Language | Characteristics | Detec/Recog Task |
|---|---|---|---|---|---|---|
| End2End | ==== | ==== | ==== | ==== | ==== | ==== |
| ICDAR03 (2003) | 509 (258/251) | 2276 (1110/1156) | Horizontal | EN | - | ✓/✓ |
| ICDAR13 Scene Text(2013) | 462 (229/233) | - (848/1095) | Horizontal | EN | - | ✓/✓ |
| ICDAR15 Incidental Text(2015) | 1500 (1000/500) | - (-/-) | Multi-Oriented | EN | Blur, Small, Defocused | ✓/✓ |
| ICDAR17 / RCTW (2017) | 12263 (8034/4229) | - (-/-) | Multi-Oriented | CN | - | ✓/✓ |
| Total-Text (2017) | 1555 (1255/300) | - (-/-) | Multi-Oriented, Curved | EN, CN | Irregular polygon label | ✓/✓ |
| SVT (2010) | 350 (100/250) | 904 (257/647) | Horizontal | EN | - | ✓/✓ |
| KAIST (2010) | 3000 (-/-) | 5000 (-/-) | Horizontal | EN, KO | Distorted | ✓/✓ |
| NEOCR (2011) | 659 (-/-) | 5238 (-/-) | Multi-oriented | 8 langs | - | ✓/✓ |
| CUTE (2014) or here | 80 (-/80) | - (-/-) | Curved | EN | - | ✓/✓ |
| CTW (2017) | 32K ( 25K/6K) | 1M ( 812K/205K) | Multi-Oriented | CN | Fine-grained annotation | ✓/✓ |
| CASIA-10K (2018) | 10K (7K/3K) | - (-/-) | Multi-Oriented | CN | ✓/✓ | |
| Detection Only | ==== | ==== | ==== | ==== | ==== | ==== |
| OSTD (2011) | 89 (-/-) | 218 (-/-) | Multi-oriented | EN | - | ✓/- |
| MSRA-TD500 (2012) | 500 (300/200) | 1719 (1068/651) | Multi-Oriented | EN, CN | Long text | ✓/- |
| HUST-TR400 (2014) | 400 (400/-) | - (-/-) | Multi-Oriented | EN, CN | Long text | ✓/- |
| ICDAR17 / RRC-MLT (2017) | 18000 (9000/9000) | - (-/-) | Multi-Oriented | 9 langs | - | ✓/- |
| CTW1500 (2017) | 1500 (1000/500) | - (-/-) | Multi-Oriented, Curved | EN | Bounding box with_14_ vertexes | ✓/- |
| Recognition Only | ==== | ==== | ==== | ==== | ==== | ==== |
| Char74k (2009) | 74107 (-/-) | 74107 (-/-) | Horizontal | EN, Kannada | Character label | -/✓ |
| IIIT 5K-Word (2012) | 5000 (-/-) | 5000 (2000/3000) | Horizontal | - | cropped | -/✓ |
| SVHN (2010) | - (-/-) | 600000 (-/-) | Horizontal | - | House number digits | -/✓ |
| SVTP (2013) | 639 (-/639) | - (-/-) | EN | Distorted | -/✓ |
Evaluation
Detection Metrics
- Precision ($P$): the proportion of predicted text instances that can be matched to gt labels.
- Recall ($R$): the porportion of gt labels that have correspondents in the predicted list.
- F1-Score
$$ F_1 = \frac{2PR}{P+R} $$
- And others
Recognition Metrics
Character-level(#characters are recognized)/word level(whether the predicted word exactly the same as gt)
Applications
- Automatic Data Entry
- Identity Authentication
- Augmented Computer Vision
- Intelligence Content Analysis